How to Deploy Object Detection Models on Android with Flutter




Table of Contents
🚑 Deployment: Where ML models go to die
In this post, I will outline the basic steps to deploy ML models onto lightweight mobile devices easily, quickly and for free.
tip
By the end of this post, you will learn about:
- Leveraging Hugging Face infrastructure to host models.
- Deploying on any edge device using REST API.
- Displaying the results on a Flutter Android app.
According to Gartner, more than 85% of machine learning (ML) models never made it into production. This trend is expected to continue further this year in 2022.
In other words, despite all the promises and hype around ML, most models fail to deliver in a production environment. According to Barr Moses, CEO, Monte Carlo, deployment is one of the critical points where many models fail.
So what exactly is the deployment of ML model? Simply put, deployment is making a model’s capability or insight available to other users or systems - Luigi Patruno.
🏹 Begin with deployment in mind
Many ML researchers take pride in training bleeding-edge models with state-of-the-art (SOTA) results on datasets. As a researcher, I understand how deeply satisfying it feels to accomplish that.
Unfortunately, many of these so-called “SOTA models” will end up on preprints, Jupyter notebooks, or in some obscure repository, nobody cares about after the initial hype.
Eventually, they are forgotten and lost in the ocean of newer “SOTA models”. To make things worse, the obsession with chasing after “SOTA models” often causes researchers to lose track of the end goal of building the model - deployment.

Source: ClearML on Reddit.
Hence, as ML engineers, it is very helpful if we build models with deployment in mind, as the end result.
Because only when a model is deployed can it add value to businesses or organizations. This is the beginning of getting a model into production.
Deployment is unfortunately a messy and complicated topic in MLOps - too deep for us to cover here. Luckily, that is not the purpose of this post.
tip
My objective in this post is to show you how you can deploy an ML model easily on a mobile device without getting your hands dirty with servers, backends or Kubernetes.
The following figure shows the deployment architecture that allows us to accomplish that. Deployment architecture.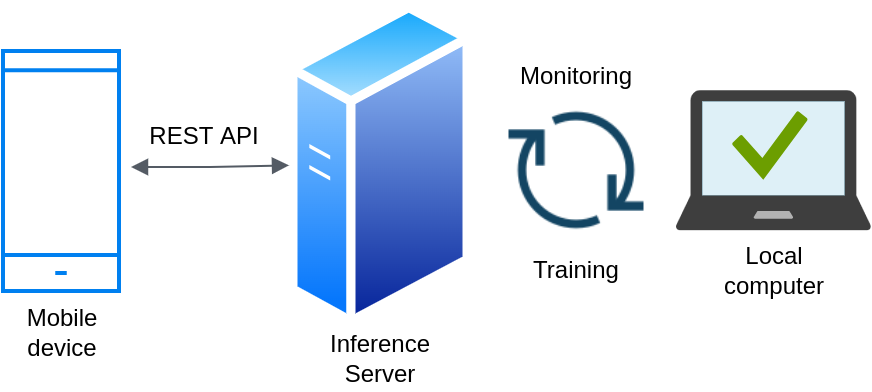
🤗 Hosting a model on Hugging Face
The first piece of the puzzle is to host our model on some cloud infrastructure. In this post, let’s use a free service known as Hugging Face Spaces.
Spaces is a platform where anyone can upload their model and share it with the world.
If you head to https://huggingface.co/spaces, you will find thousands of models that researchers made freely available online.
These models are hosted on Spaces for demo and sharing purposes. But they can be scaled up into full-fledge production with the Inference API.
Let’s set up a Space to host our model. If you’re unsure how to do that, I wrote a recent guide on how to set your own Space with the Gradio app here.
In this post, I will use an IceVision object detection model trained to detect microalgae cells from an image. I trained this model in under a minute with only 17 labeled images. Here is how I did it.
Once the Space is set, we will have a Gradio interface like the following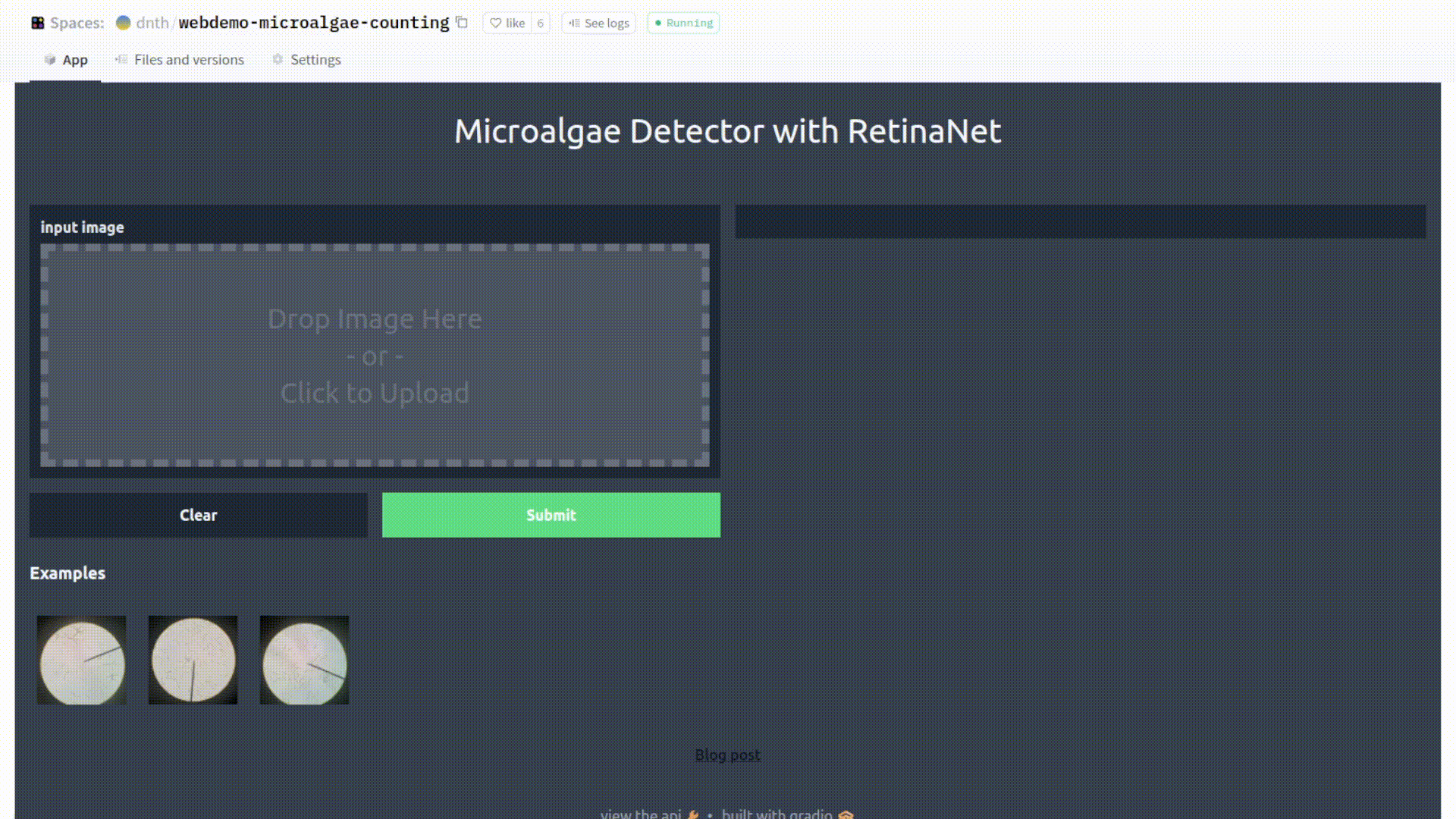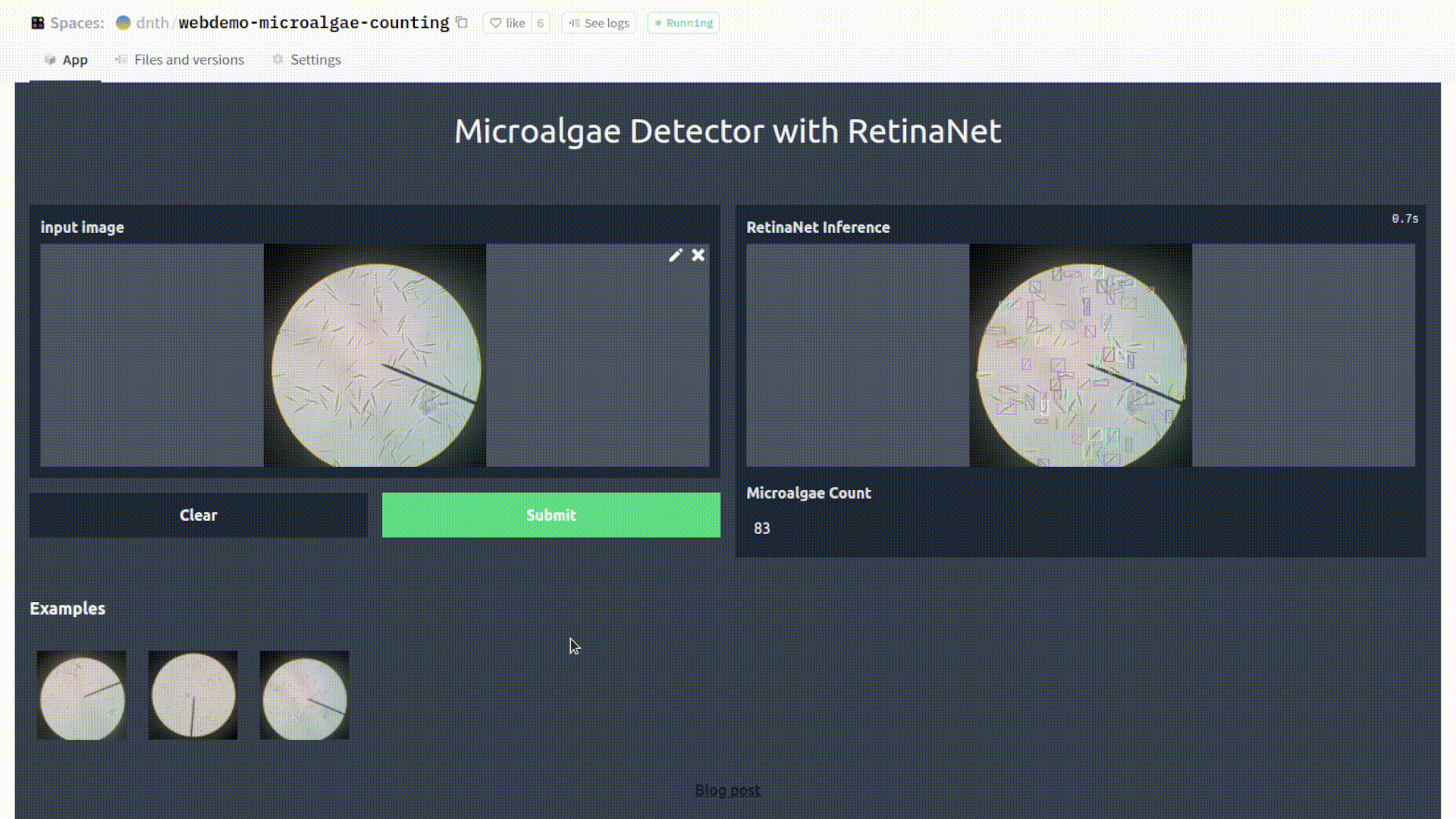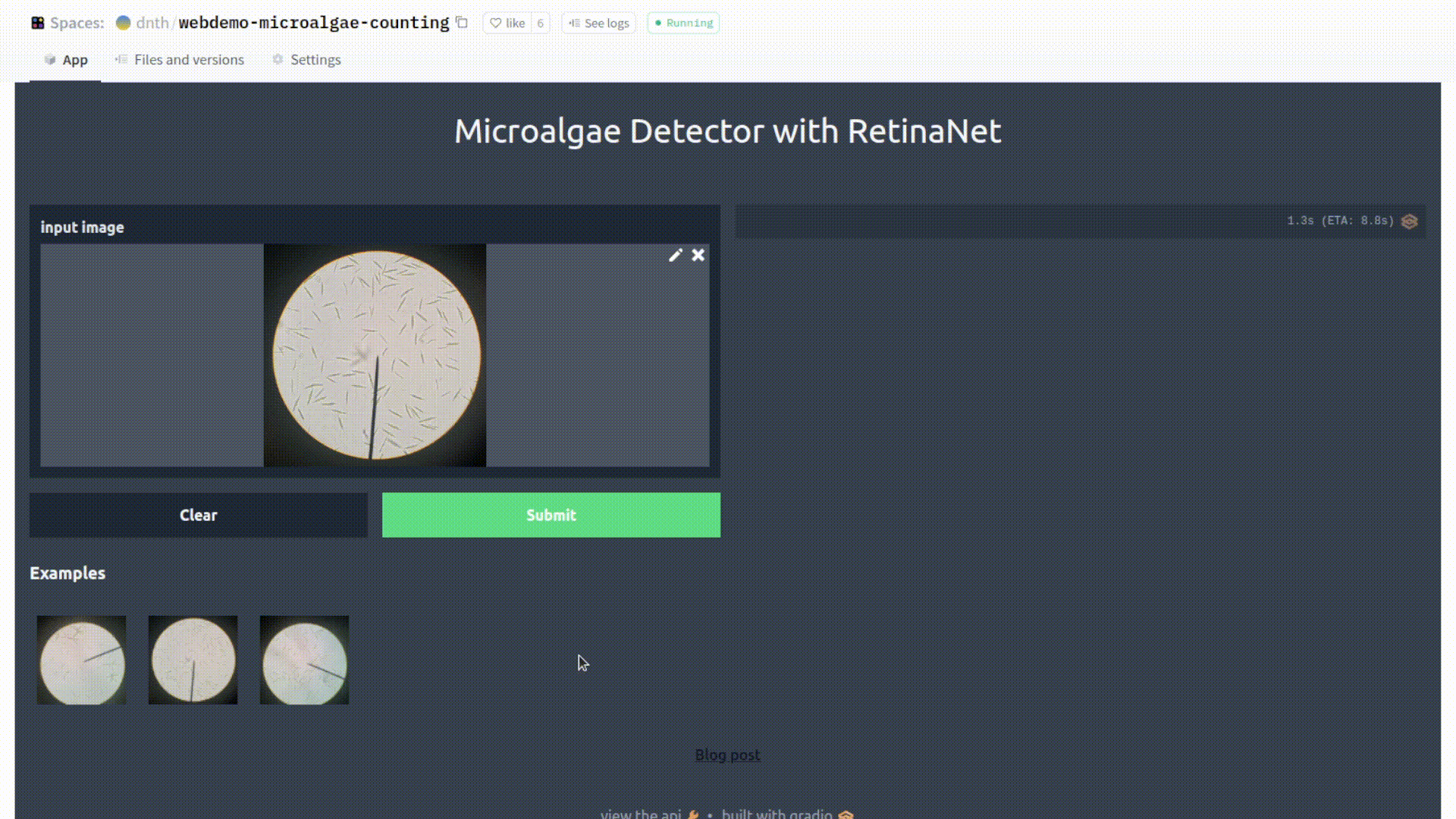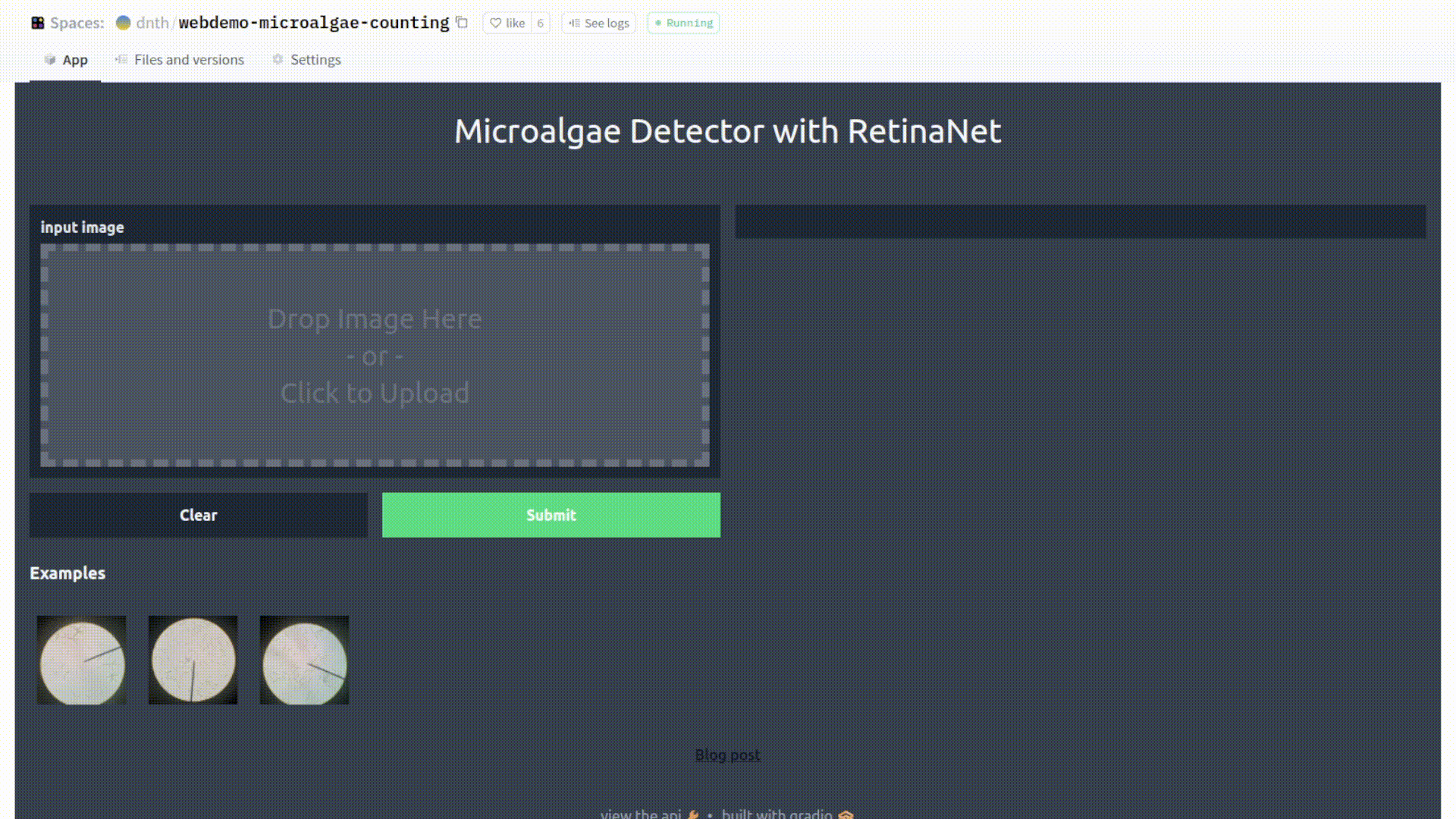
This Space is now ready to be shared with anyone with an internet connection and a browser. Try the live demo below 👇👇👇
But what if we want to make the app work on a mobile device without using a browser? Enter 👇
📞 Calling the HTTP Endpoint
One neat feature of the Gradio app is it exposes the model through a RESTful API. This makes the model prediction accessible via HTTP request which we can conveniently use on any mobile device!
Now, any computationally lightweight device can make use of the model’s prediction just by running a simple HTTP call. All the heavy lifting is taken care of by the Hugging Face infrastructure.
tip
This can be a game-changer if the model is complex and the edge device is not powerful enough to run the model - which is a common scenario.
Additionally, this also reduces deployment hardware costs, because now any lightweight, portable mobile device with an internet connection can leverage the model’s cell counting capability.
The figure below shows the endpoint for us to call the model.
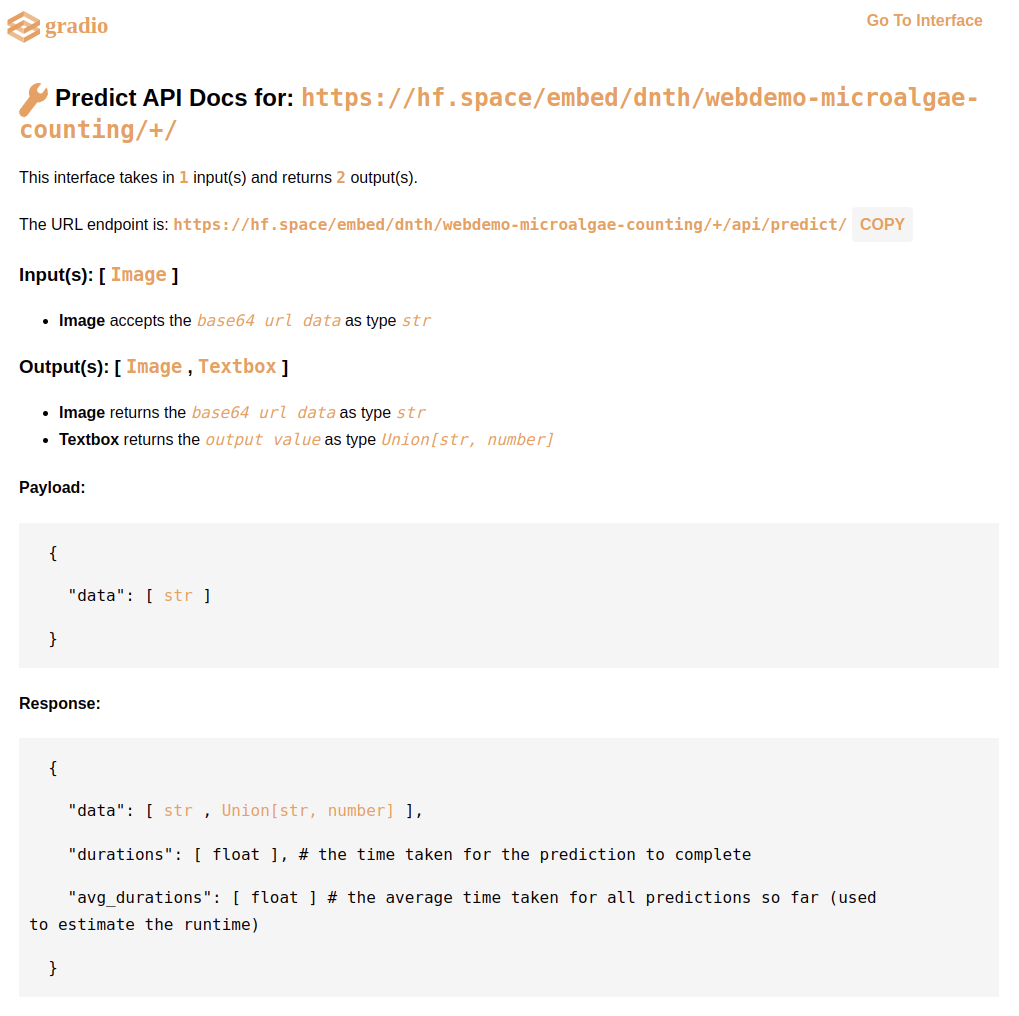
As shown, the input to the model is an image, and the output, an image (with bounding boxes) and also a value of the microalgae count. You can check out the API here.
If you’d like to test the HTTP endpoint live, head to the API page as the following figure.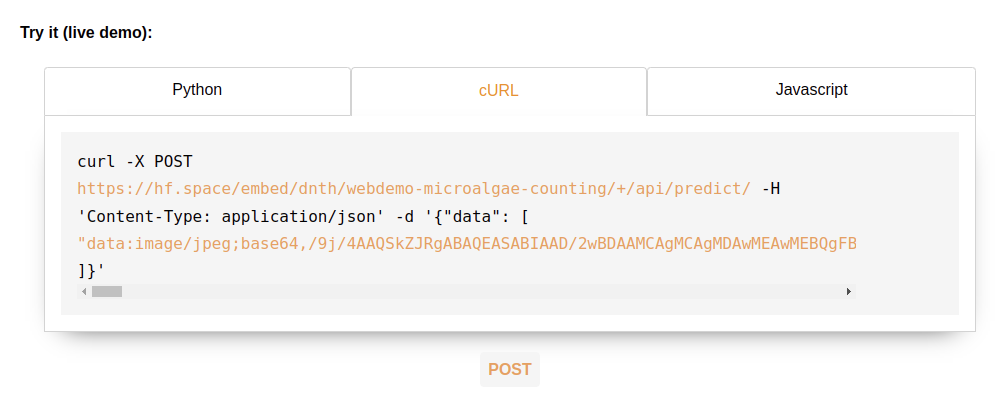
Alternatively, you can also try them out on your computer with curl:
curl -X POST https://hf.space/embed/dnth/webdemo-microalgae-counting/+/api/predict/
-H 'Content-Type: application/json'
-d '{"data": ["data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD/2wBDAAMCAgMCAgMDAwMEAwMEBQgFBQQEBQoHB..."]}'
Let’s copy the URL endpoint and use in the next section
📲 Displaying results in Flutter
We will be using Flutter to make a simple Android app that sends an image and receive the bounding box prediction via HTTP calls.
Flutter uses the Dart programming language that makes it incredibly easy to construct a graphical user interface (GUI). I omit the codes to construct the GUI in this post for simplicity. Let me know if you’d like to access it. There are also tons of tutorials on how to construct the GUI so, I will not cover them here too.
The snippet of code that allows us to perform the HTTP call to the Hugging Face server is as follows.
| |
The detectImage function in line 4 takes in a single parameter String base64 format image and returns a Map which consists of the image with bounding box and the microalgae count in line 22.
The URL endpoint that we copied from the previous section is on line 7.
The screen recording below illustrates the Flutter app sending a sample image to the Hugging Face inference server and getting a response on the number of detected microalgae cells and the image with all the bounding boxes.
I published the app on Google Playstore. If you like, try them out here.
I’ve also published another similar app that deploys a deep learning classifier model (trained with Fastai) that categorizes paddy leaf diseases here using the same approach outlined in this post.
💡 Up Next
That’s about it! In this post hopefully, it’s clear now that deploying deep learning models on mobile devices doesn’t need to be complicated - at least in the beginning when it’s critical to gain users’ feedback before deciding if it’s right to scale up.
Caveat: I do acknowledge that the approach in this post might not be optimal in some circumstances, especially if you have thousands of users on your app.
For that, I would recommend scaling up to use the Hugging Face Inference API - a fully hosted production-ready solution 👇.
It is also possible now to deploy Hugging Face models on AWS Sagemaker for serverless inference. Check them out here.
Finally, you could also use the same Flutter codebase and export it into an iOS, Windows, or even a Web app. This is the beauty of using Flutter for front-end development. Code once, and export to multiple platforms.
🙏 Comments & Feedback
If you have any questions, comments, or feedback, please leave them on the following Twitter post or drop me a message.
Deploying deep learning models on mobile devices can be a pain.
— Dickson Neoh 🚀 (@dicksonneoh7) April 21, 2022
I'll walk you through simple steps I took to deploy an object detection model trained with IceVision on Android using @huggingface Spaces and @FlutterDev - for free.
A thread 👇👇https://t.co/2XRWHlTZ7p
- GitHub
- Scholar
- Telegram
🤟 Follow me
Don't want to miss any of my future content? Follow me on Twitter and LinkedIn where I share these tips in bite-size posts.
🔄 Share this post
❤️ Show some love
Creating free ML contents doesn't pay my bills. Support me in creating more free contents like these. Consider buying me a coffee. Your support means a lot to me.
